Intelligence Artificielle & Sciences des données
Depuis 2021, je développe des méthodes utilisant l’intelligence artificielle pour analyser des textes contenant des millions de caractères afin de les classer, les catégoriser et les comparer. L’objectif de ces travaux est de développer les méthodes les plus adaptées aux données et aux questions de recherche, tout en nourrissant une réflexion épistémologique sur la place de ces outils en sociologie et sur les précautions méthodologiques qu’exige leur utilisation.
Pour ce faire, je teste divers outils parmi lesquels des algorithmes d’apprentissage supervisé tels que les Machines à Vecteurs de Support (SVM), des réseaux de neurones récurrents (RNN), en particulier les réseaux de type Long Short-Term Memory (LSTM) ou les Transformers, des modèles reposant sur des mécanismes d’attention pour prendre en compte le contexte, tels que BERT (Bidirectional Encoder Representations from Transformers) ou RoBERTa.
Projets de recherches réalisés
1. Analyse des messages postés sur Twitter (tweets) de 2012 à 2021 sur les véhicules autonomes
L’objectif du projet a été d’identifier l’évolution des émotions (négatives, neutres et positives) exprimées dans les messages postés sur Twitter ("X") au moyen de diverses techniques supervisées d’apprentissage profond. Après avoir collecté près de 7 millions de tweets, nous avons sélectionné les tweets contenant au moins un mot émotionnel ou à valence émotionnelle au moyen d’un dictionnaire de 189 801 mots.
L’une des étapes a ensuite été de tester deux types de labéllisations (multiclasse ou multilabel) et de tester plusieurs modèles pour obtenir les meilleures performances. L’analyse des émotions au moyen de l’algorithme Binary Segmentation (bibliothèque Ruptures) a permis de distinguer deux grandes périodes (Figure 1) : la première (2012-2016), positive, est portée par les bénéfices espérés portés par cette nouvelle technologie et la deuxième (2016-2021), négative, se concentre sur les risques et accidents causés par les véhicules autonomes en circulation.
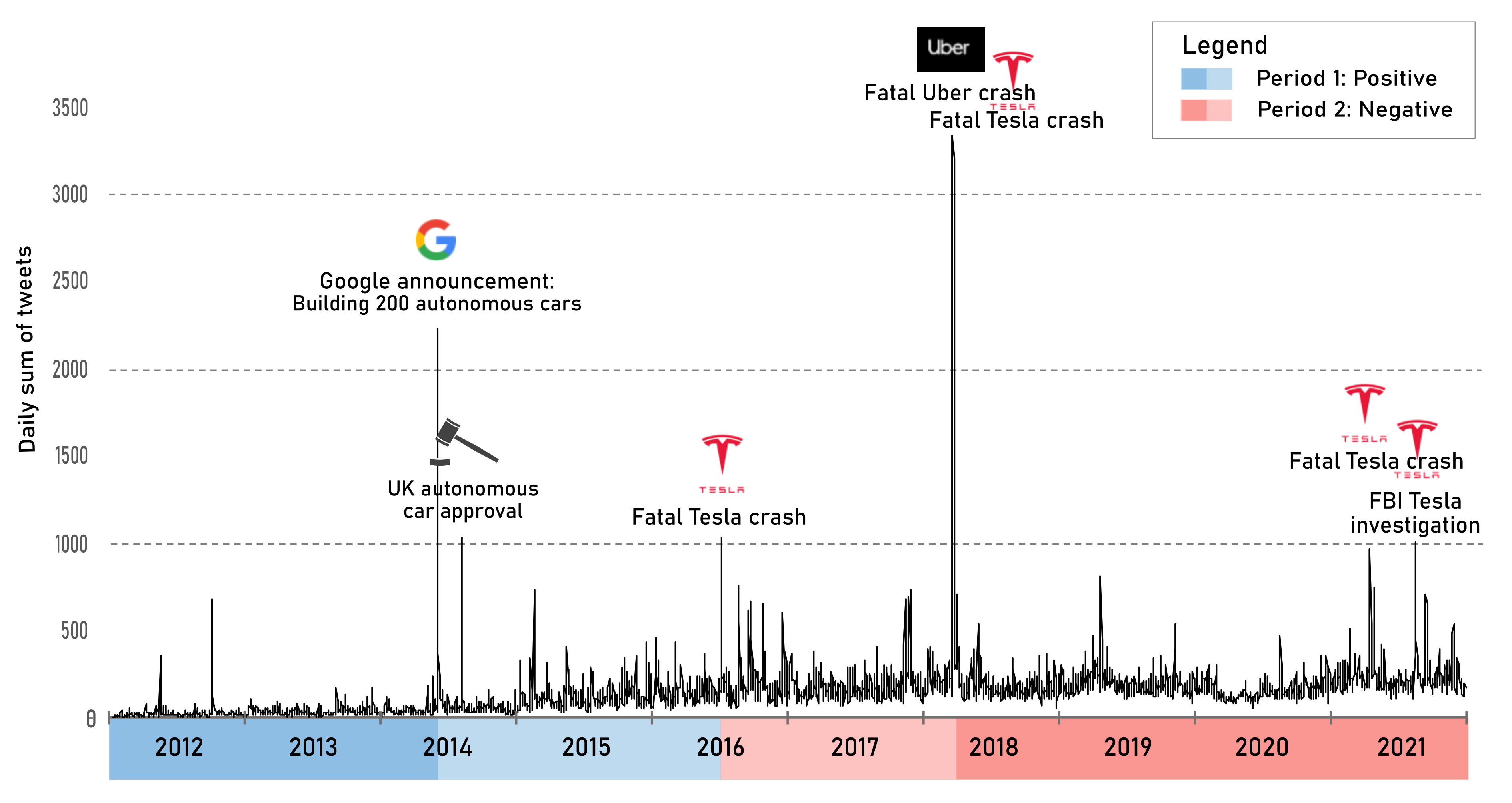
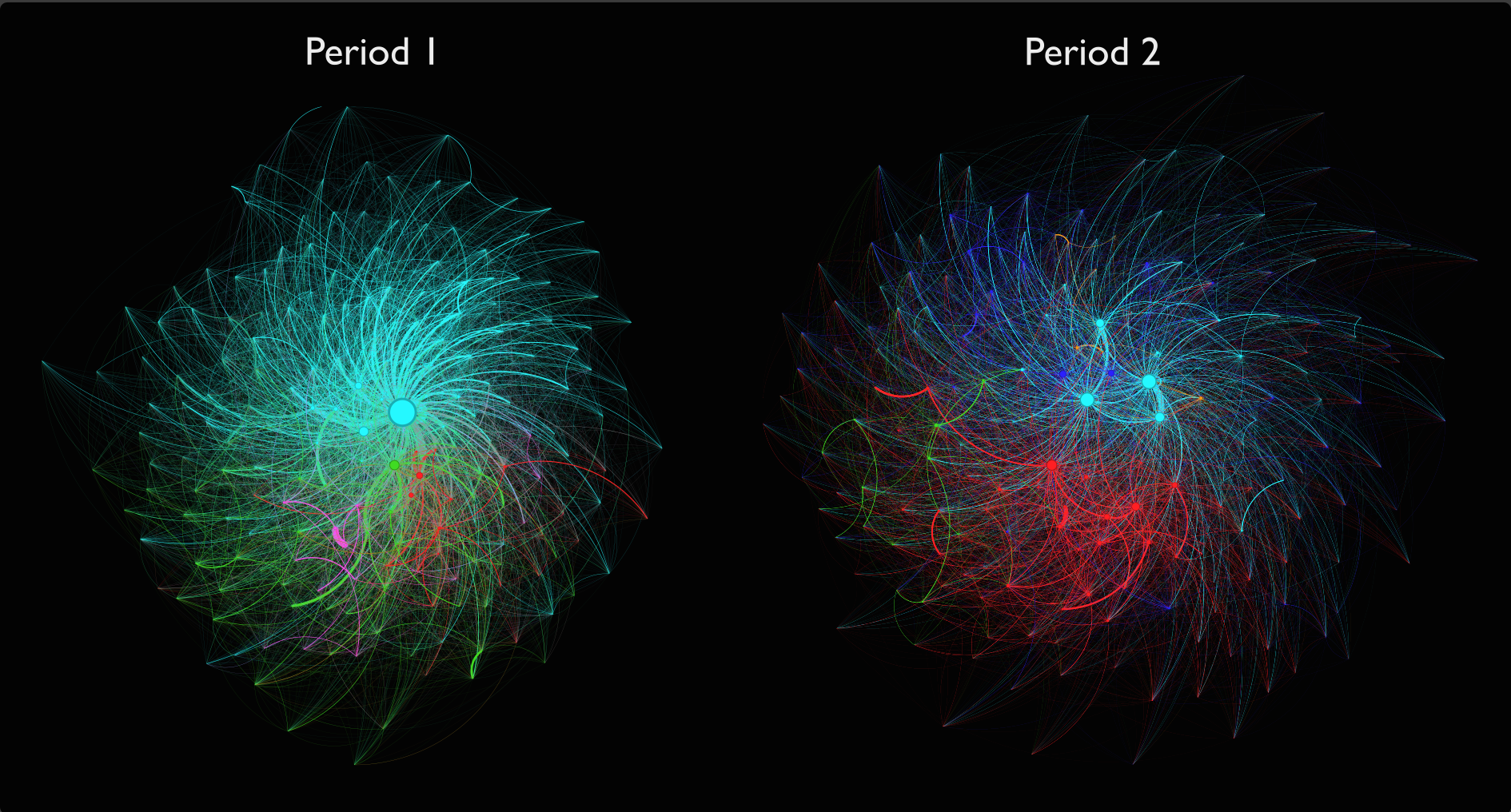
Le projet a également inclus de l’analyse de contenu au moyen de text analytics, text analysis et knowledge graphs (bibliothèque NetworkX). Les graphes de connaissance ont l’avantage de faciliter l’exploration des mots les plus utilisés au cours d’une période et de les regrouper en classes. Dans la Figure 2, ci-dessous, on peut voir que l’espoir généré par la technologie (en bleu) est prédominante au cours de la première période, alors que la peur des accidents et des décès (en rouge) devient centrale au cours de la seconde période. Les accidents de véhicules autonomes ont donc eu un impact sur la manière avec laquelle les citoyens perçoivent les véhicules autonomes.
2. Analyse des tweets postés sur la vaccination contre la Covid-19 et le pass sanitaire
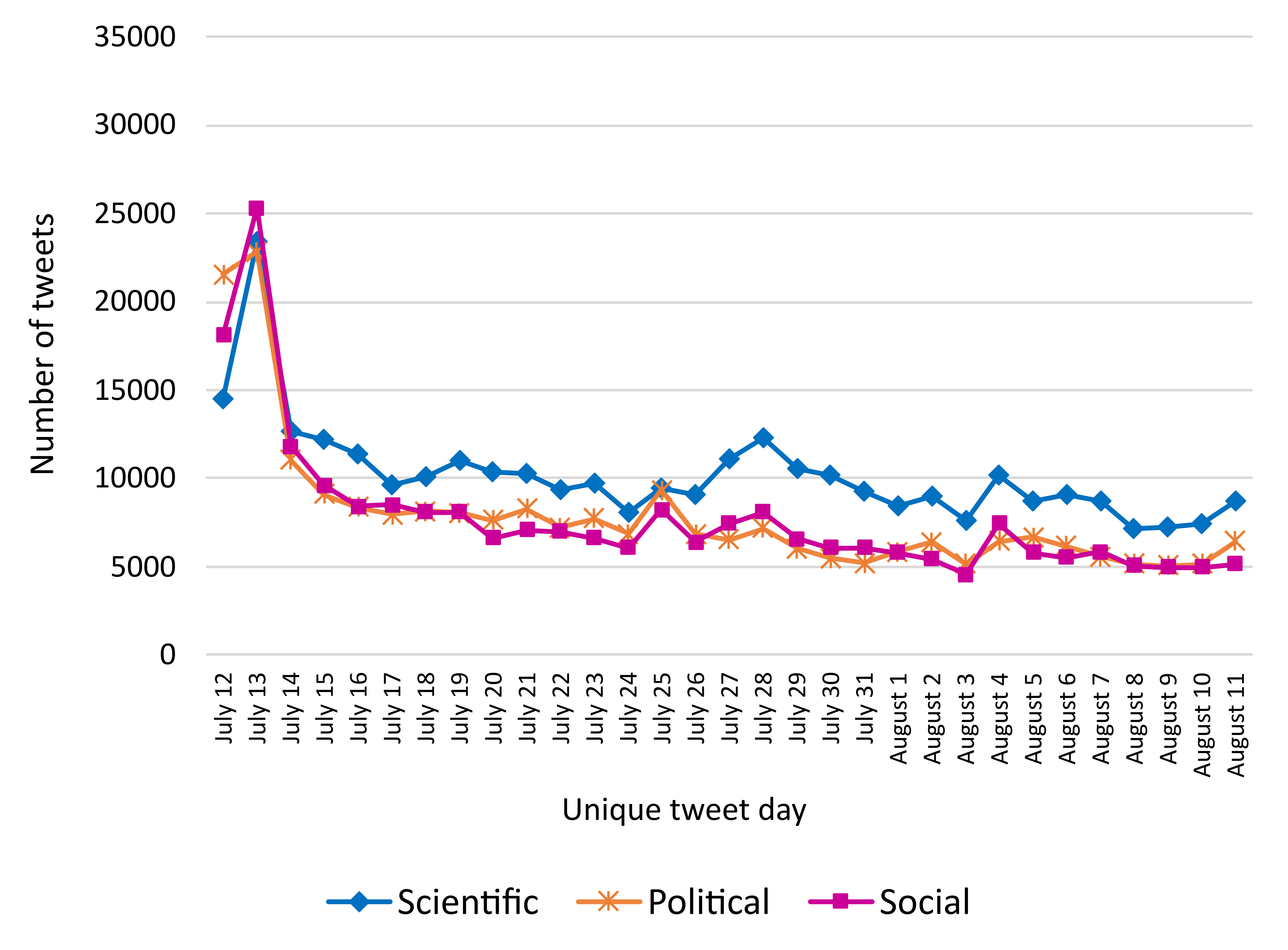
L’objectif du projet était d’identifier l’évolution des émotions (négatives, neutres et positives) exprimées dans les messages postés sur Twitter ("X") afin d’identifier la part des messages en faveur ou en défaveur des vaccins et le contenu argumentatif utilisé. Pour ce faire, deux types de catégorisations ont été utilisées au moyen d’une approche supervisée (des labellisations manuelles ont servi à entraîner le modèle CamemBERT) : 1/ les sentiments (négatif, neutre, positif) et 2/ les arguments (politique, scientifique et social).
L’étude a permis de montrer que si les messages étaient plus souvent négatifs, les citoyens mobilisaient des travaux scientifiques ou pseudoscientifiques pour contester une décision politique, à savoir l’imposition du pass sanitaire et l’obligation vaccinale des soignants (Figure 3).
3. Analyse du contenu des sites Internet promouvant des remèdes naturels contre le cancer et accessibles au moyen du moteur de recherche Google
L’objectif du projet était de mesurer le niveau d’exposition des patients aux promesses de guérison sur Internet et d’identifier le contenu de la désinformation diffusée sur les 50 pages Internet web-scrapées.
L’étude repose sur l’usage de la bibliothèque Beautiful Soup pour extraire les pages Internet et du text mining pour explorer leur contenu. Le texte a été lemmatisé (regroupés en lemmes) au moyen de la bibliothèque Stanza, la plus adaptée au français grâce à ses modèles reposant sur l’intelligence artificielle. Les schémas ont été générés au moyen des bibliothèques Seaborn et Matplotlib. Les analyses menées ont permis de montrer que les promesses de guérison naturelle du cancer promouvaient plus souvent le curcuma, les vitamines et les fruits et légumes (Figure 4).
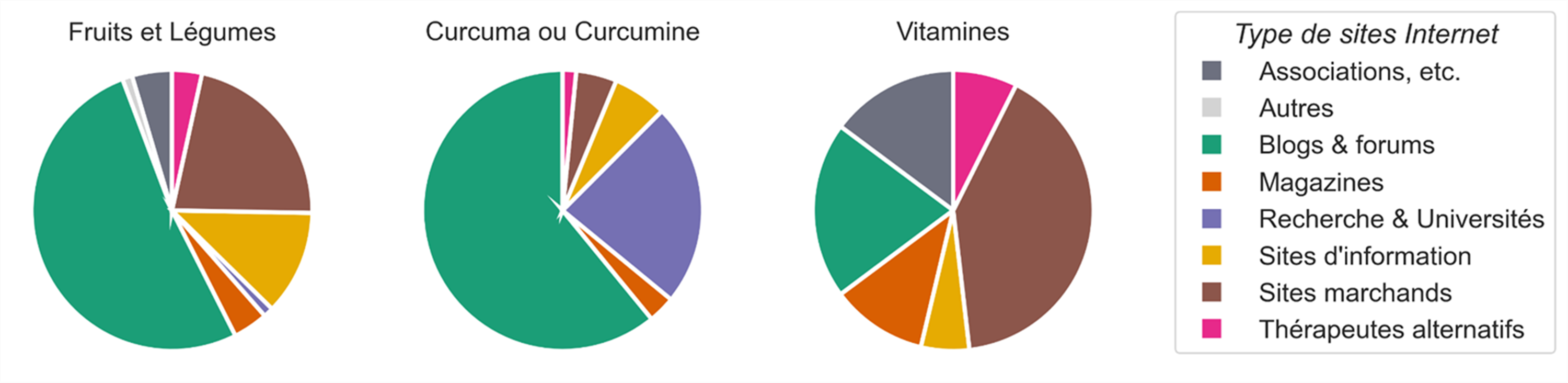
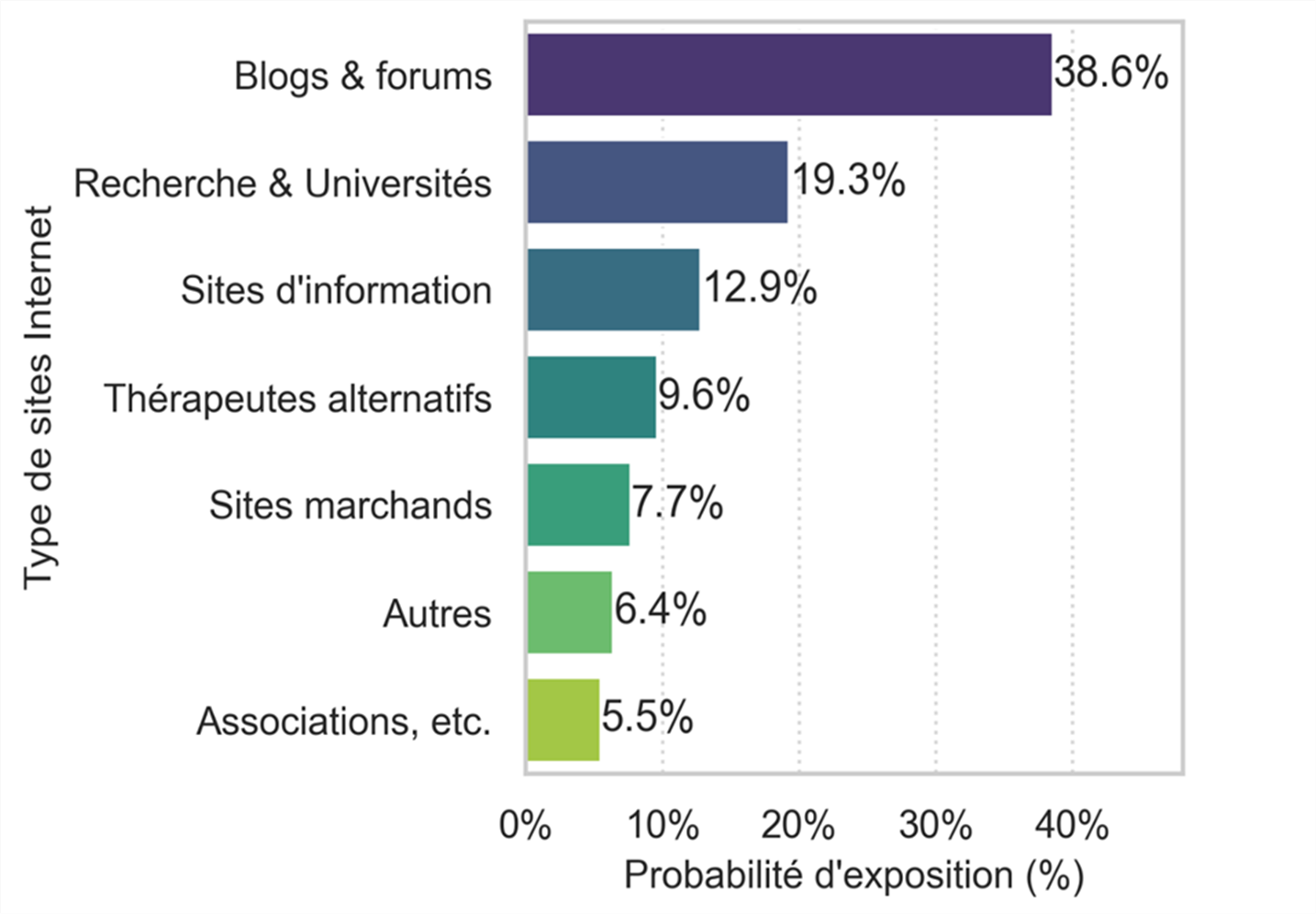
De plus, un calcul de probabilité d’exposition en fonction du rang d’apparition des pages Internet et du type de site Internet a permis de montrer que les internautes sont plus souvent exposés aux blogs (Figure 5). Ces blogs promeuvent le curcuma, les fruits et légumes pour guérir du cancer au moyen d’arguments pseudo-scientifiques laissant penser que des preuves scientifiques sont disponibles à l’appui de leurs affirmations.
Bibliothèques Python et environnement de travail
Environnement de travail

Visualisations & manipulation des données

Apprentissage profond


Analyses statistiques

Traitement de données textuelles
